下面我将为您提供一个全面、结构化的指南,涵盖目的、方法、工具、流程、挑战与最佳实践。
为什么需要邮件舆情信息收集?(目的与价值)
在进行具体操作前,首先要明确收集的目的,这决定了后续所有工作的方向。
(图片来源网络,侵删)
- 品牌声誉管理:实时监测客户、合作伙伴和公众对品牌的评价,及时发现负面信息并应对。
- 产品与服务反馈:收集用户对新产品、功能或服务的直接反馈,用于产品迭代和优化。
- 市场趋势洞察:通过分析邮件中的讨论,了解行业动态、竞争对手动向和消费者偏好变化。
- 危机预警:当大量负面邮件或特定关键词(如“投诉”、“差评”、“问题”)出现时,可以作为早期预警信号。
- 客户满意度分析:量化分析客户在售前、售中、售后的情绪,评估服务质量。
- 营销活动效果评估:分析营销活动后收到的邮件,评估用户反应和活动效果。
从哪里收集邮件舆情?(信息来源)
邮件舆情信息的来源多种多样,需要根据您的业务目标来确定重点关注的渠道。
| 来源类型 | 具体渠道 | 价值与特点 |
|---|---|---|
| 内部邮件 | 客服支持邮件 | 核心来源:直接反映客户问题和情绪,是产品改进和服务优化的第一手资料。 |
| 市场/销售团队邮件 | 包含潜在客户、合作伙伴的询问、抱怨和意向,是市场趋势和销售线索的重要来源。 | |
| 员工内部邮件 | 了解员工对公司政策、文化、管理的看法,有助于内部管理和文化建设。 | |
| 外部邮件 | 媒体关系邮件 | 与记者、编辑的沟通,了解媒体对品牌的报道倾向和潜在的新闻线索。 |
| 合作伙伴邮件 | 了解上下游合作伙伴的合作满意度、潜在风险和新的合作机会。 | |
| 用户注册/订阅邮件 | 用户通过邮件提交的反馈、建议或问题。 | |
| 公开邮件列表/论坛 | 如Google Groups、Yahoo Groups等特定领域的公开讨论邮件列表。 |
如何收集和分析?(方法与流程)
这是一个从数据到洞察的完整闭环流程。
数据收集与预处理
-
数据获取:
- API接口:如果使用Gmail、Outlook等企业服务,可以通过其官方API(如Microsoft Graph API, Gmail API)获取邮件数据,这是最规范、最高效的方式。
- 邮件转发:设置特定邮箱(如
feedback@company.com)接收所有相关邮件,然后将该邮箱的邮件自动转发到一个分析系统。 - 邮件客户端插件:对于个人或小规模分析,可以使用邮件客户端的插件或第三方工具来导出邮件。
- 爬虫技术:针对公开的邮件列表或论坛,可以使用爬虫技术抓取公开的邮件内容。(注意:需遵守网站的
robots.txt协议和相关法律法规,尊重隐私)。
-
数据预处理:
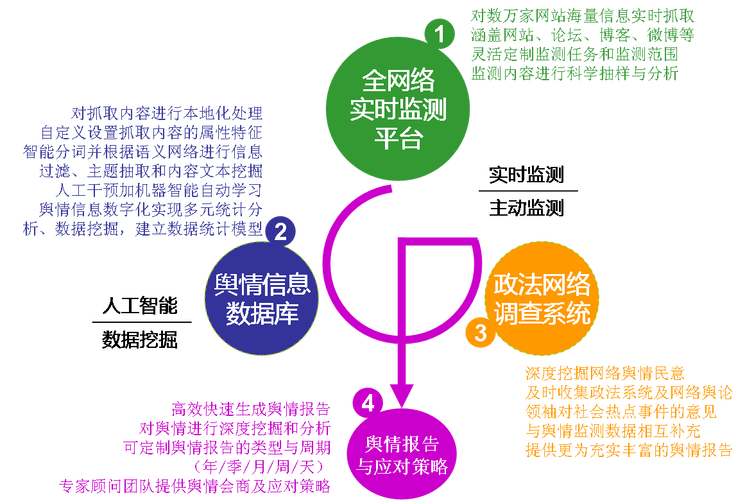 (图片来源网络,侵删)
(图片来源网络,侵删)- 去重:去除重复的邮件,避免分析偏差。
- 清洗:移除无关内容,如HTML标签、广告、签名档、附件等。
- 分词:将连续的文本切分成独立的词语或词组。
- 标准化:统一大小写、处理同义词(如“不好”和“差”)、处理拼写错误。
舆情分析与洞察
这是核心环节,主要依赖自然语言处理技术。
-
情感分析:
- 目标:判断邮件内容是正面、负面还是中性。
- 方法:
- 关键词匹配:基于预设的情感词典(如正面词:“好”、“赞”、“满意”;负面词:“差”、“垃圾”、“失望”)进行打分,简单但有效。
- 机器学习模型:使用训练好的分类模型(如朴素贝叶斯、SVM、深度学习模型)进行更精准的情感判断,能更好地理解上下文。
-
主题/实体识别:
- 目标:了解大家在讨论什么,以及提到了哪些具体对象。
- 方法:
- 主题模型:如LDA(Latent Dirichlet Allocation),可以从大量邮件中自动发现隐藏的主题,可能发现“物流慢”、“客服态度差”、“产品功能强大”等主题。
- 命名实体识别:识别文本中的人名、地名、组织名、产品名等,可以快速定位到是“A产品”的“B功能”出了问题。
-
热点与趋势分析:
- 目标:发现当前最受关注的话题和舆情变化趋势。
- 方法:
- 词频统计:统计高频词汇,了解讨论焦点。
- 时间序列分析:将舆情数据按时间(天/周)聚合,分析情感得分或话题热度的变化,发现突发事件或营销活动的影响。
-
关键意见领袖识别:
- 目标:找出在邮件讨论中具有影响力的人物。
- 方法:分析邮件的回复链、发件人频率、其观点被引用的次数等,识别出核心的讨论者和影响者。
可视化与报告
将分析结果以直观的方式呈现给决策者。
- 仪表盘:创建实时更新的可视化仪表盘,展示关键指标,如:
- 每日/每周邮件总量
- 正面/负面/中性情感比例(饼图)
- 情感得分趋势线图
- 热门话题词云
- 负面邮件预警列表
- 自动化报告:定期(如每周/每月)生成PDF或HTML格式的分析报告,自动发送给相关负责人。
使用什么工具?(工具推荐)
根据您的规模、预算和技术能力,可以选择不同的工具组合。
| 工具类型 | 推荐工具 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 一体化舆情平台 | Brandwatch, Meltwater, Cision, 热云识微 | 大型企业,需要监控全网(包括邮件、社交媒体、新闻等)数据 | 功能强大,数据源广,分析专业,可视化效果好 | 价格昂贵,定制化程度相对较低 |
| 开源工具/框架 | Python (NLTK, spaCy, Scikit-learn), Elasticsearch, Logstash | 技术能力强,希望高度定制化,预算有限 | 完全免费,灵活可控,可针对特定需求深度开发 | 需要专业的技术团队开发和维护,部署和维护成本高 |
| SaaS分析服务 | MonkeyLearn, Rosette API, Google Cloud NLP | 中小企业,希望快速集成NLP功能到现有系统 | 按需付费,API调用简单,上手快 | 功能相对固定,可能无法满足复杂需求 |
| 自研系统 | 结合数据库、爬虫、NLP库自行开发 | 需求非常独特,有强大研发团队的核心企业 | 完全贴合业务,数据安全可控 | 开发周期长,投入巨大,持续维护成本高 |
面临的挑战与最佳实践
主要挑战
- 隐私与合规:这是最大的挑战,未经用户同意收集和分析其邮件内容可能违反GDPR、CCPA等隐私法规。务必确保在合法合规的框架内进行,
- 仅分析用户主动发送的反馈邮件。
- 对内部员工邮件的分析需有明确的政策授权。
- 对数据进行脱敏处理,去除个人身份信息。
- 非结构化数据格式多样(HTML/纯文本)、口语化、多义词、错别字等,给NLP分析带来很大难度。
- 数据量庞大:对于大型企业,每日邮件量可能达到数百万,对存储和计算能力要求很高。
- 上下文理解:机器很难完全理解讽刺、幽默、行业黑话等复杂语境,可能导致情感分析偏差。
最佳实践
- 明确目标,聚焦核心:不要试图分析所有邮件,先从最重要的来源(如客服邮件)开始,定义清晰的分析目标。
- 人机结合,人工复核:AI自动化处理效率高,但准确性有限,对于关键负面舆情或复杂案例,必须进行人工复核和深度分析。
- 建立预警机制:设置负面关键词和情感阈值,一旦触发,立即通过邮件、短信或Slack等工具通知相关负责人,实现快速响应。
- 闭环管理,驱动行动:收集和分析不是终点,最重要的是将洞察转化为行动,
- 将产品问题反馈给研发团队。
- 将服务投诉反馈给客服团队进行回访。
- 将市场趋势反馈给市场部门。
- 持续迭代优化模型:定期用新的标注数据训练和优化你的情感分析模型,不断提高其准确性。
通过以上系统性的方法,您可以有效地将海量的邮件数据转化为有价值的商业洞察,从而更好地管理品牌声誉、优化产品服务和把握市场机遇。


